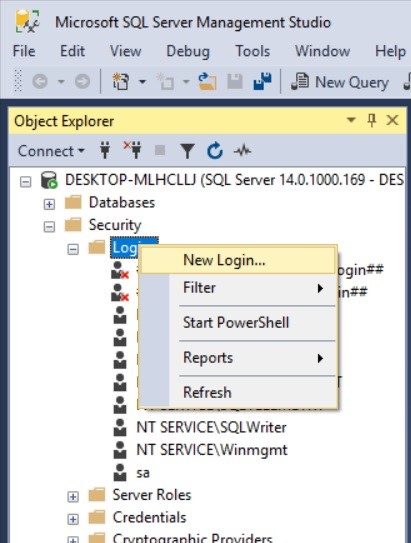
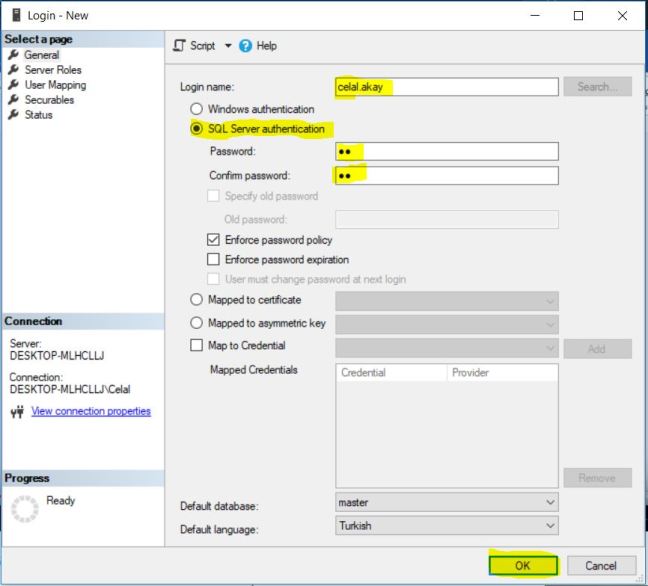
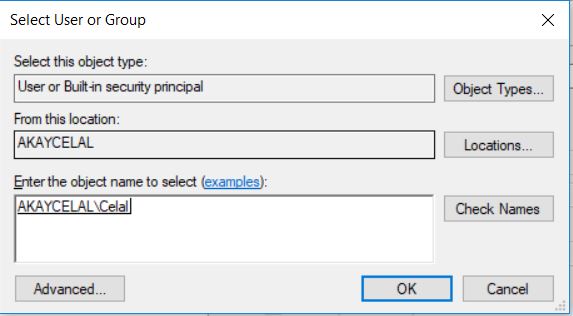
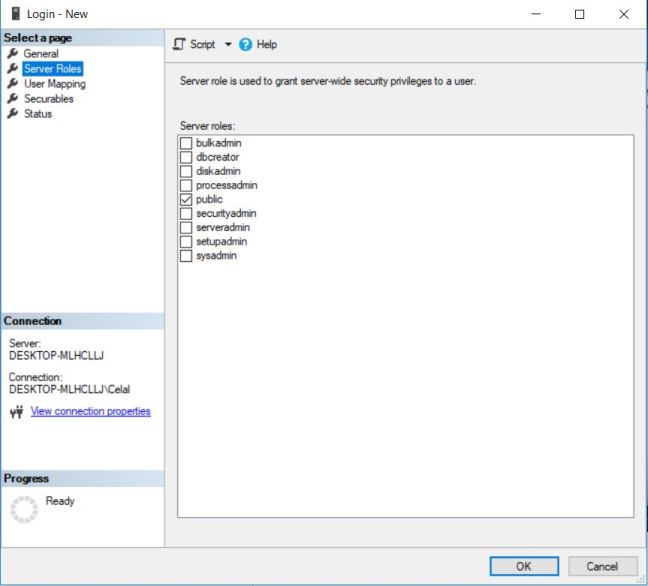
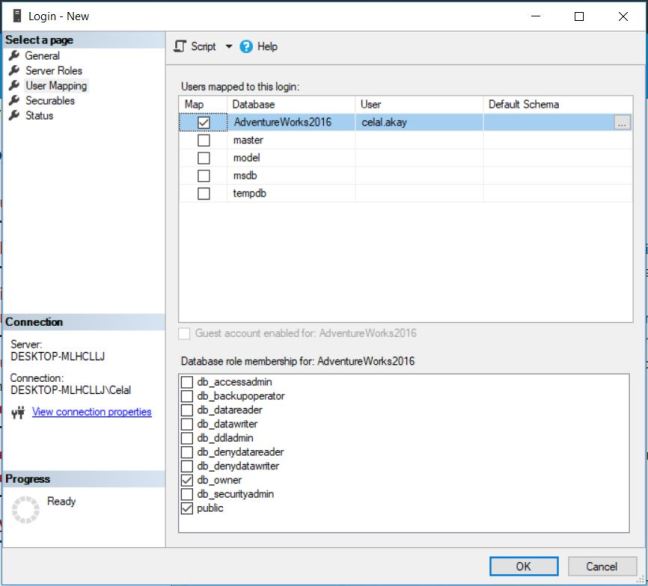
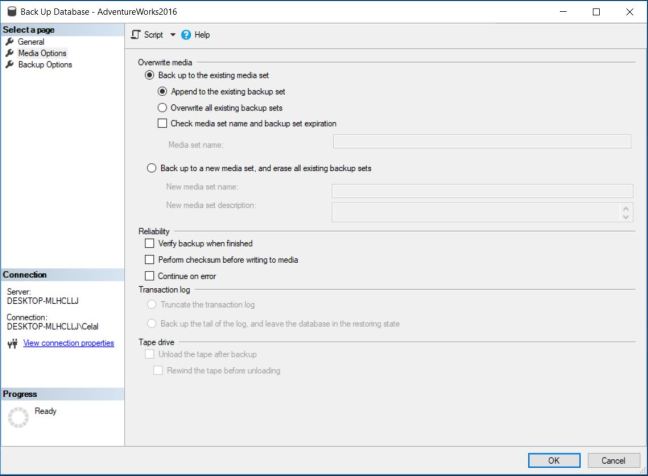
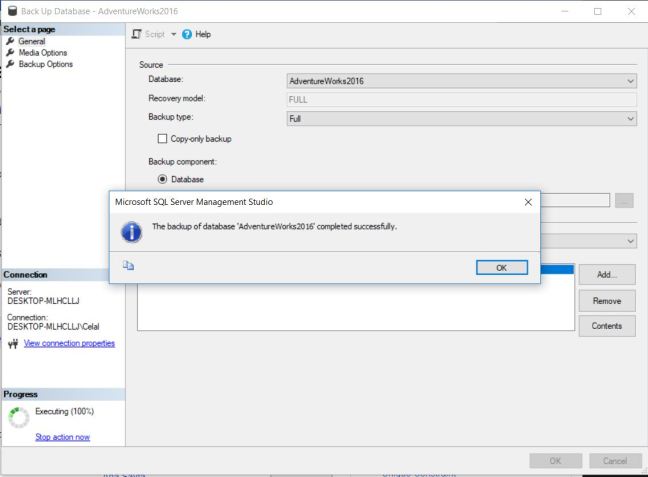
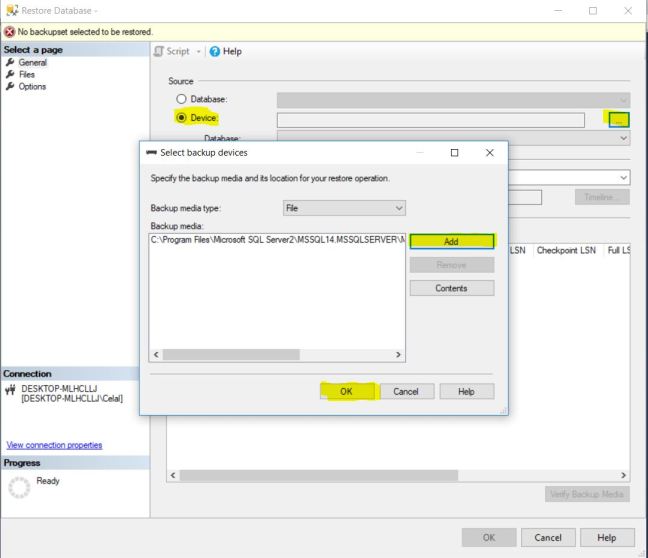
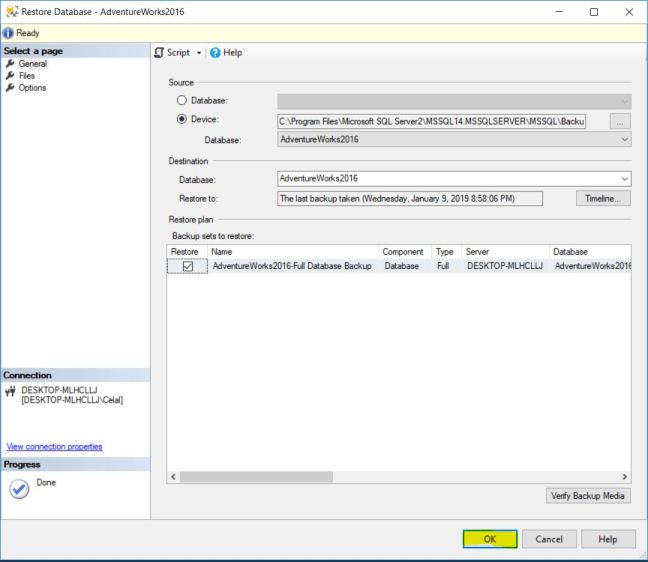
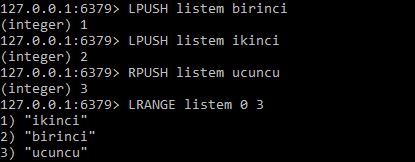
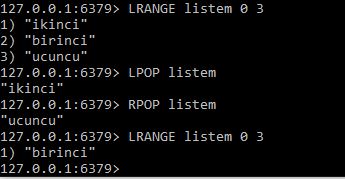
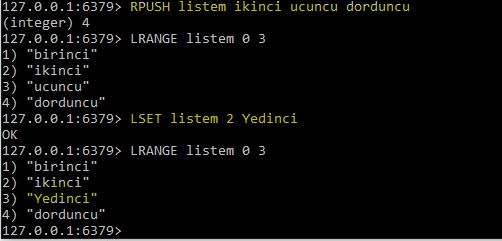
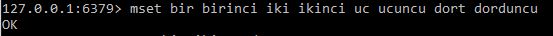MongoDB nedir ? sorusuna cevap vermeden önce muhtemelen NoSQL nedir ? sorusuna cevap vermek daha iyi olacaktır zira MongoDB bir NoSQL veri tabanı sistemidir.
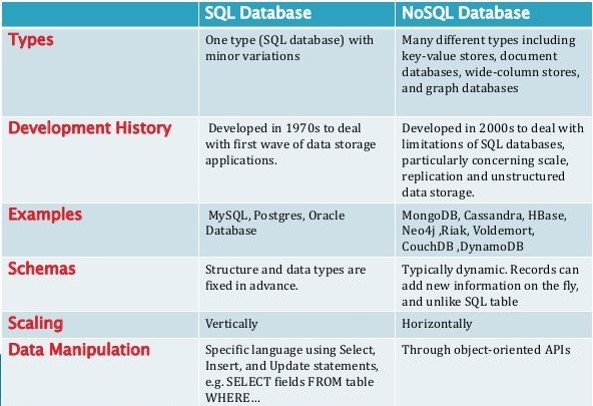
NoSQL nedir ?
Genel olarak MongoDB üzerinde duracağımız içinNoSQL konusuna bilgi olması amaçlı değinmek istiyorum. NoSQL adı ” Not Only SQL” den gelmektedir yani sadece SQL değil, ne demek bu ? RDBMS sistemlerden farklı bir yapıda olduğunu anlatıyor aslında, bunun en büyük göstergesi de ilişkisel olmayan veri tabanları olmalarıdır desek yanlış olmaz. RDBMS sistemleri ACID(Atomicity Consistency Isolation Durability) kurallarına uymak zorundadır yani bir RDBMS veritabanı sistemi aynı anda tüm bu kuralları yerine getirmek zorundadır fakat NoSQL sistemlerde böyle bir zorunluluk bulunmuyor NoSQL sistemler benim daha performanslı olmamı sana daha hızlı işlem yaptırmamı istiyorsan biraz nazımı da çekip bazı kurallarda bana tolerans göstereceksin diyor adeta, NoSQL göreceli olarak senaryonuza bağlı olarak RDBMS sistemlerden çok daha performanslı çalışabilir fakat güvenlik ve veri bütünlüğü konusunda şuan için RDBMSlerden daha geride bulunuyorlar.
NoSQL vertabanı çeşitleri
Döküman (Document) tabanlı: Bu sistemlerde bir kayıt döküman olarak isimlendirilir. Dökümanlar genelde JSON formatında tutulur. Bu dökümanların içerisinde sınırsız alan oluşturulabilir. MongoDB, CouchDB, Bigtable, DynamoDB HBase, Cassandra ve Amazon SimpleDB bunlara örnektir.
Anahtar / Değer (Key / Value) tabanlı: Bu sistemlerde anahtara karşılık gelen tek bir bilgi bulunur. Yani kolon kavramı yoktur. Azure Table Storage, MemcacheDB ve Berkeley DB bunlara örnektir.
Grafik (Graph) tabanlı: Diğerlerinden farklı olarak verilerin arasındaki ilişkiyi de tutan, Graph theory modelindeki sistemlerdir. Neo4J, FlockDB bunlara örnektir.
Bazı kaynaklarda döküman tabanlı veritabanı sistemlerinden bazıları Kolon tabanlı olarak da gösterilmektedir. Bizim değineceğimiz MongoDB veritabanı sistemi de Döküman tabanlı sistemler arasında yer almaktadır.
Burada değinmek istediğim bir diğer konu olarak CAP teoremini biraz anlatmakta fayda var böylelikle sistem farklılıkları biraz daha net anlaşılmış olacaktır.
Consistency(Tutarlılık) : Verilerin çıkan sonuçla olan tutarlılık derecesi
Availability(Kullanılabilirlik) : Sistemin aynı anda bir kaç kullanıcı tarafından kullanılabilir olma durumu
Partition-Tolerance(Bölme): Verilerin parçalara ayrılarak işleme sokulma durumu
Aşağıdaki şekilde hangi veritabanlarının hangi şartları sağladığını daha iyi şekilde anlayabiliriz. Bu durumda MongoDB bize Tutarlılık ve Verilerin bölümlendirilmesi açısından olanak sağladığını göstermektedir.
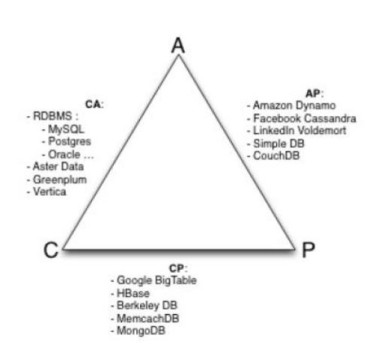
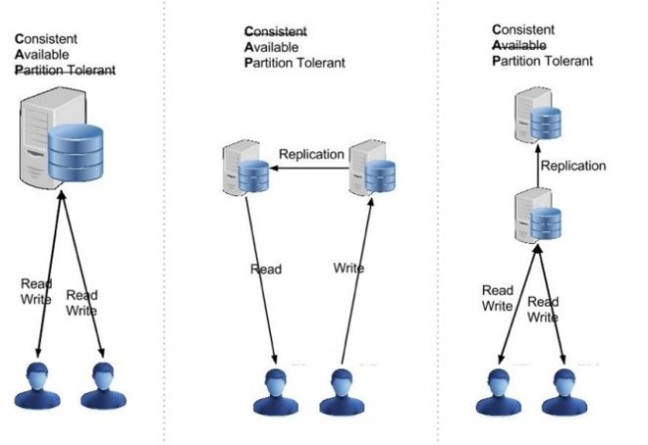
Aşağıdaki şekilde ise herhangi bir özelliği kullanamadığımızda kullanıcıların nasıl bir sistem ile karşı karşıya olduğunu göstermektedir.
MONGODB
MongoDB NoSql veri tabanı sistemlerinin Doküman tabanlı sistemlerinden biridir. Veriler JSON\BSON formatında saklanır.

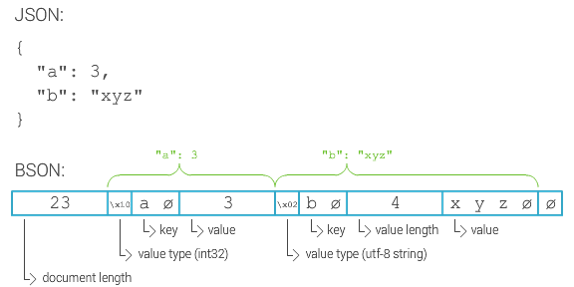
Peki JSON ve BSON nedir ?
JSON verilerin XML benzeri formatta ama daha da sıkıştırılmış ve boyutu daha küçültülmüş halde tutulmasıdır. Böylelikle boyutun küçülmesinin yanında işlem hızı da daha iyi seviyede olmaktadır.
BSON ise JSON verilerin encode edilmiş halidir yani bir kademe daha sıkıştırılmış hali olarak da düşünülebilir.
MongoDB ye dönecek olursak MongoDB de veriler belirli ID’ler tanımlanarak tutulmaktadır ve bu sayede sorgulamalarda yüksek performans göstermektedir.
Diğer NoSql sistemlere oranla daha zengin bir sorgulama diline sahiptir.
Veriler yatay ölçeklendirme ile yedeklenebildiği için kullanılabilirlik oranı oldukça yüksektir.
MongoDB NoSql veri tabanlarının doküman tabanlı veri tabanlarından biridir ve en çok tercih edilen veri tabanları arasında bulunmaktadır. MongoDB’yi diğer NoSql veri tabanlarından ayıran kendine has bazı özellikleri vardır. Bunlar;
Sorgu(query) desteği. Pekçok NoSQL çözümü veriye sadece anahtarlar(key) üzerinden erişme olanağı sağlarken, MongoDB istenilen alanlar ve belirli aralıklara(range query) göre, ayrıca düzenli ifadelerle(regular expression) de sorgulama imkanı sunuyor.
İkincil(secondary) index desteği. İstenilen alanlara göre sorgulama yanı sıra, bu alanları secondary index olarak tanımlayabilmek. Bu Sqlde kullanılan non-clustered index olarak da düşünülebilir.
MongoDB Altyapısı
Aggregation: Dağınık halde bulunan verileri toplayıp gruplandırmak ve bunlar üzerinden gerekli işlemleri yapmak.

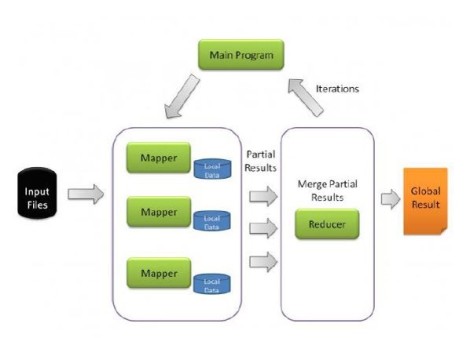
Map-Reduce desteği: Böl gönder, topla gönder. Burada kullanıcının sisteme yüklediği veriler mapperlar ile parçalara bölünür ve gerekli alanlara dağıtılır, bu sayede işlemler daha hızlı yapılır ve sistemin her alanına aktarılan yük dahada azaltılmış olur, sistem tarafından gerekli işlemler yapıldıktan sonra bu veriler Reducer’lar ile tekrar bir araya getirilir ve kullanıcıya aktarılır.
Text Search: MongoDB içerisinde bir metin arama desteği bulunmaktadır. Bunun için bir string ifadeyi $text fonksiyonunu kullanarak arayabilirsiniz. Bana sorarsanız mongodb’nin en güzel özelliklerinden biri de budur istediğiniz zaman hiç bir zorluk yaşamadan bir metin arayabilir ve bulabilirsiniz bu işlemi RDBMS sistemlerde MsSQLde yapmak için Full text search özelliğini kullanmak gerek bazen bunun için taklalar atmanız bile gerekebiliyor.

Data Models: MongoDB’nin veri tutma biçimi Sqlden farklı bir halde bulunmaktadır. Bir dizi içerisinde string ve integer ifade bulunabilir. Bu özellikte RDBMS sistemlerden fark olarak düşünebileceğimiz bir özellik.

Indexes: MongoDB de indexler birkaç şekilde tanımlanabilir. Bunlar;
–Single Field
–Compound Index
–Multikey Index
–Geospatial Index
–Text Index
–Hashed Index
Replication: MongoDB’nin herhangi bir server hatası durumunda kendini güvenceye alması. RDBMS sistemlerdeki Disaster Recovery’ler benzeri olarak da düşünülebilir. Ana sunucunun her hangi bir sorunla karşılaşması tehlikesine karşın yedek sunucular ile verilerin yedeklenmesi ve ana sunucuda sorun gerçekleştiğinde yedek sunucunun ana sunucu görevini üstlenip veri kayıplarını engellemesi için gerekli bir özelliktir.
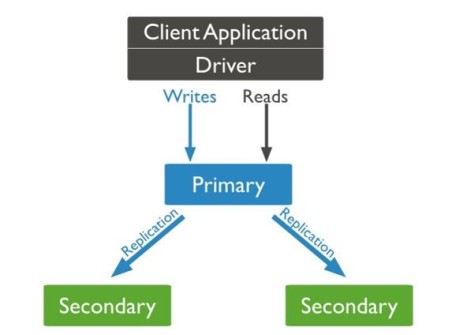
Master-Slave Replication desteği: Yazma ve okuma işlemlerini ayrı sunuculara yönlendirebilme. Replication özelliğinin bir alt özelliği olarak da düşünülebilir. Yine aynı şekilde ana sunucu ve yedek sunucular oluşturulabilir. Burada ek olarak yazma ve okuma işlemleri ayrı sunuculardan yapılabilir böylelikle sunucular üzerindeki trafik ve yük azaltılacağından performans açısından önemli bir artış daha sağlanabilir.
Sharding desteği: Büyük ölçekli verilerin sunucular arasında paylaştırılması özelliği. MongoDB de performansın en öncelikli konu olduğundan bahsetmiştik bu nedenle bazen veriler çok büyük boyutlara ulaştığında tek bir sunucu artık bizim için yetersiz bir hal alabilir bu nedenle yeni sunucular ile yatay büyümeye giderek veriler bu sunuculara dağıtılır ve yük azaltılmış olur.
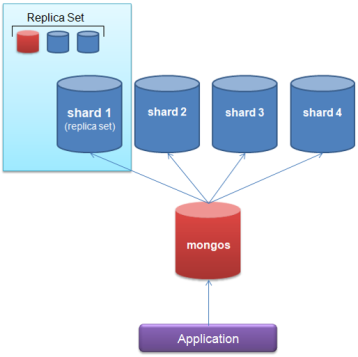
Yatay(Horizontal) – Dikey(Vertical) büyüme
NoSQL sistemler ve MongoDB yatay Büyüme ile RDBMS sistemler Dikey büyüme ile büyüme işlemi yapar demiştik peki nedir bu büyüme çeşitleri;
Dikey büyüme: Sunucu özelliklerini arttırma. Burada elimizde bulunan mevcut sunucunun özellikleri(CPU, Memory, Disk vb.) arttırılır. Bu bi açıdan her konuda çok maliyetli olabilir ve bir sunucunun özelliklerinini ne kadar arttırabilirsiniz ki ? eğer küçük veriler üzerinden çalışıyorsanız belki orta ölçekli bir sunucu işinizi görebilir fakat çok büyük verilere sahip sistemler düşünüldüğünde dikey büyüme aşırı bir uğraş ve maliyet gerektirebilir.
Yatay büyüme: Sunucu arttırma. Bu işlemde ise mevcut sunucunuz üzerinde herhangi bir değişiklik ve özellik arttırımı yapmakla uğraşmadan aynı özelliklerde ya da ihtiyaç doğrultusunda farklı özelliklerde bir sunucuyu daha sunucunuza bağlayarak ihtiyacınızı giderebilirsiniz. Google’lın sunucu dünyasına baktığımızda yatay büyüme ile sunucularını arttırdığını görebiliriz.
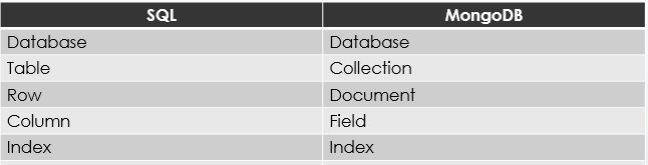
Sql’de ve MongoDB’de tanımlama farklılıkları da aşağıdaki gibidir.
Şimdi isterseniz MongoDB yi iki tane NoSQL veritabanı sistemi olan Cassandra ve CouchDB ile karşılaştıralım kısaca;
Cassandra
Cassandra da NoSql bir veri tabanı sistemi olup Facebook ve Apache tarafından geliştirilen açık kaynak kodlu bir veri tabanı sistemidir. Burada da veriler JSON ve XML olarak tutulmaktadır. Büyük dağıtık verilerin depolanması için MongoDB ve diğer NoSql veri tabanları gibi tercih edilen veri tabanı sistemlerinden biridir.
CouchBase
Couchdb NoSQL tabanlı, verileri JSON formatında tutan , MapReduce indeksleri için JavaScript ve kendi API’si için HTTP kullanan, Erlang ile yazılmış open source bir veritabanı sistemidir.
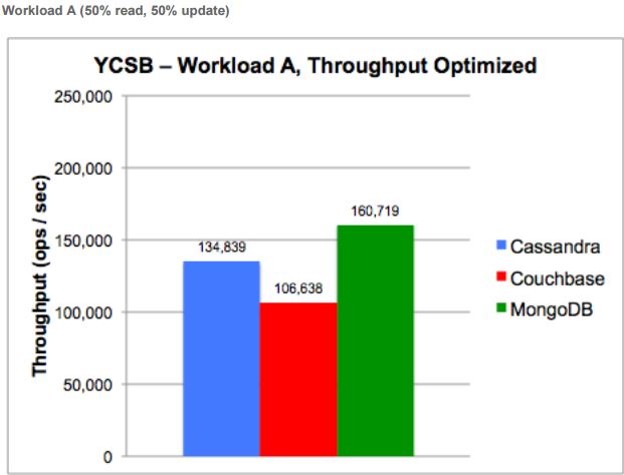
Aşağıdaki görselde üç Databasede yapılan %50 okuma ve %50 yazma işlemi baz alınmış ve saniyede yapılan işlem sayısı verilmiştir.
Buradaki görselde ise bu işlemlerin yapılış sırasında performans sürekliliği gözlemlenmiştir. Bakıldığı zaman iki veri tabanında işlem uzadıkça bir süre sonra işlemi gerçekleştirme süresi artmakta ve performansta yavaşlama olmaktadır fakat MongoDB sürekli aynı performans ile çalışmaya devam etmektedir.
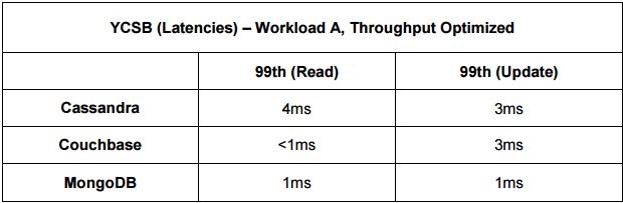
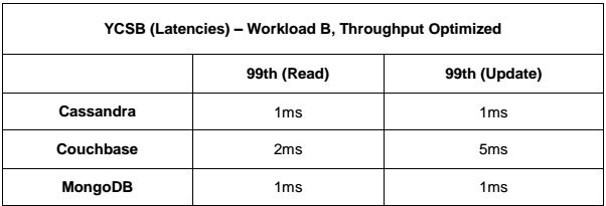
Yine bir işlemde %95 okuma ve %5 yazma işleminde MongoDBnin saniye bazında daha fazla işlem yaptığını görebiliriz.
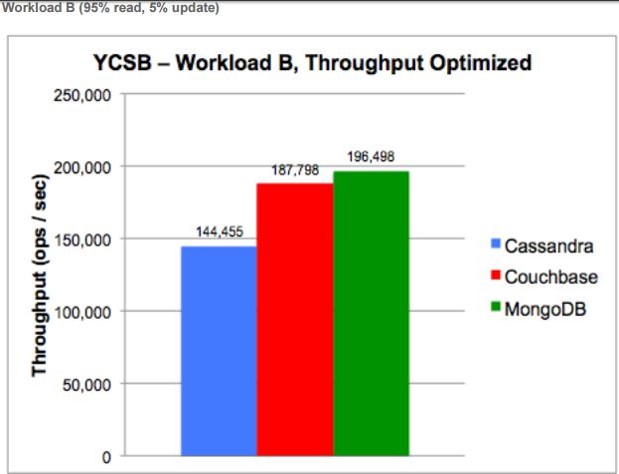
Aynı şekilde performans sürekliliğini de hiç hiç kaybetmemektedir.
MongoDB Kurulumu ve Kullanımı
Öncelikle https://www.mongodb.com/download-center?jmp=nav adresinden size uygun MongoDB sürümünü indirmeniz gerekiyor. Kurulum esnasından bazı bilgisayarlarda C: diskine bir data klasörü açmanız istenir istersenin önceden bunu hazırlayabilirsiniz çünkü verileriniz burada tutulacaktır. Ardından Command Prompt’tan (CMD) mongoDB klasörü altındaki “mongod”u çalıştırın.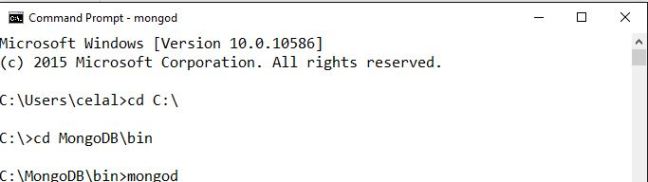
bunu çalıştırdıktan sonra aşağıdaki mesajı aldığınızda sistem server bağlantısının oluşturulduğunu belirtmektedir.
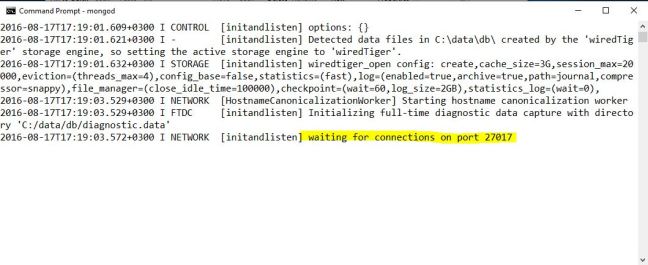
Ardından yeni bir CMD sekmesi açarak aynı klasör altındaki “mongo”yu çalıştırıyoruz.

Connection to: test mesajı sistemin artık her türlü işlemi yapmaya hazır olduğunu belirtiyor bundan sonra istediğimiz işlemleri yapabiliriz.
MongoDBde yeni bir veritabanı oluşturmak için “use db_adi”
db_adi = istediğiniz database adı
komutunu yazmanız yeterli olur eğer yazdığınız isimde bir veritabanınız bulunuyorsa sistem otomatik olarak bunu kullanıma alır ve yaptığınız değişiklikler o veritabanına yansır fakat o isimde bir veritabanı yoksa aynı kod satırı veri tabanınızı oluşturur. Eğer veri tabanını oluşturursanız fakat içine herhangi bir veri atmazsanız veritabanlarınızı listelediğinizde bu veri tabanı liste içinde yer almaz
“show dbs” ile var olan veritabanlarınızı listeleyebilirsiniz.
Yukarıdaki şekilde de görebilirsiniz normalde “yeniveritabani” adında bir veritabanımız yok ve biz bunu oluşturuyoruz fakat içine herhangi bir veri girmediğimiz için listeleme esnasında bunu göremiyoruz. Şimdi içine bir Collection ekleyelim;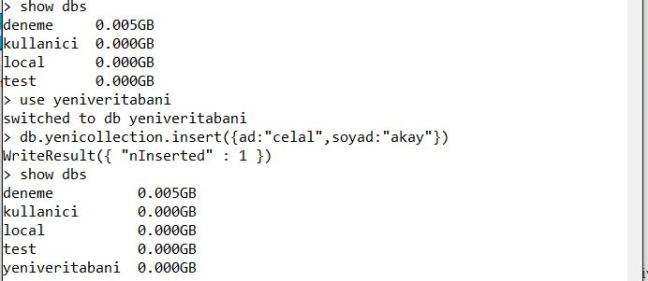
burada “db.yenicollection.insert” komutu ile yine aynı şekilde olmamasına rağmen yeni bir collection oluşturmuş ve bunun içine veri eklemiş olduk. Veritabanlarımızı listelediğimizde ise artık “yeniveritabani” adlı veritabanımızı görebiliriz.
kullanmakta olduğunuz veri tabanınızdaki collectionları görmek içinde “show collections” demeniz yeterli olacaktır.
İnsert işlemi
db.kolonadi.insert({ad:”celal”,soyad:”akay”}) basit bir insert işlemi için syntax bu şekilde olmaktadır bir veri tabanında kolona eklediğiniz veri sayısı eşit olmak zorunda değil biz burda ad ve soyad adında iki key ekledik bir sonraki işlemde daha fazla keye sahip bşr veri eklersek de herhangi bir sorun olmaz fakat RDBMS işlemler bunu kabul etmez ilk başta tablomuzda kaç kolon belirttiysek o kolon sayısı kadar veri ekleyebiliriz.

yukarıda da gördüğünüz gibi sorunsuz bir şekilde aynı collectiona istediğimiz kadar keye sahip yeni bir veri ekleyebiliriz.
Bir diğer insert işlemi olarak Sqlden farklı olarak tek key içerisine birden fazla bilgi girebilirsiniz, örneğin bir çalışan bilgisi girdiğinizde çalışanınıza ait birkaç adet mail ya da birkaç adet telefon olabilir bunların tamamını tek key içerisine girebilir başka bir alanda tutma zorunluluğundan kurtulabilirsiniz;
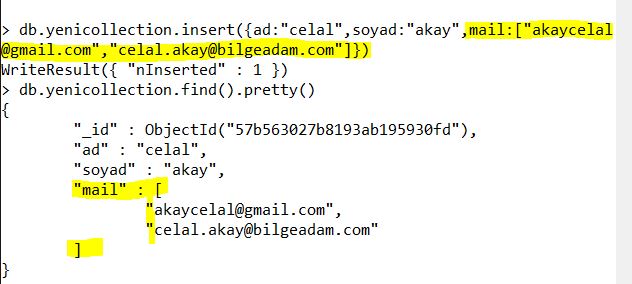
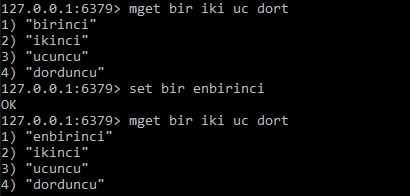
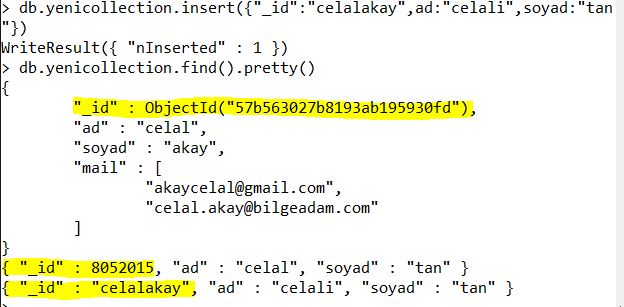
Öte yandan eklediğimiz verilere sistem otomatik olarak bir ID veriyor demiştik bunu biz istersek kendimiz tanımlayabiliyoruz. Örnek olarak aşağıdaki görsele bakabilirsiniz;
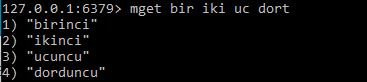
Select işlemi
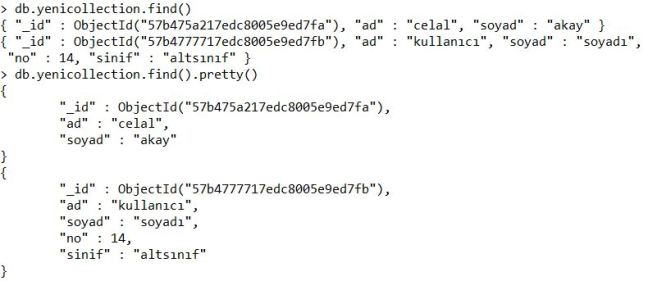
Select işlemi için “db.collectionadi.find()” yazmamız yeterli olur bu durumda o collection içerisindeki tüm verilerimiz listelenecektir.
Eğer verilerimiz düzenli okunur bir şekilde gelsin istersek “db.collectionadi.find().pretty()” yazdığımız taktirde veriler bize Json formatında dönecektir ve okunurluluğu artacaktır.
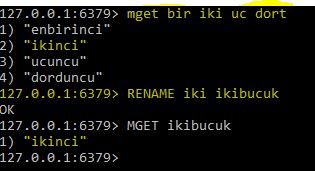
Update işlemi
MongoDB’de Update işlemi de oldukça basit bir syntax’a sahip burada Sqlden farklı bir yazım olmasıyla beraber işlem sırası da farklıdır çünkü Sql de önce hangi değerin atanacağı belirtilir sonrasında hangi şartı sağlayan verilere bu değerin atanacağı belirtilir, MongoDBde ise önce şart söylenir ardından atanacak değer belirtilir. Yazım şekli ve sonucu alttaki şekildedir;

Delete işlemi
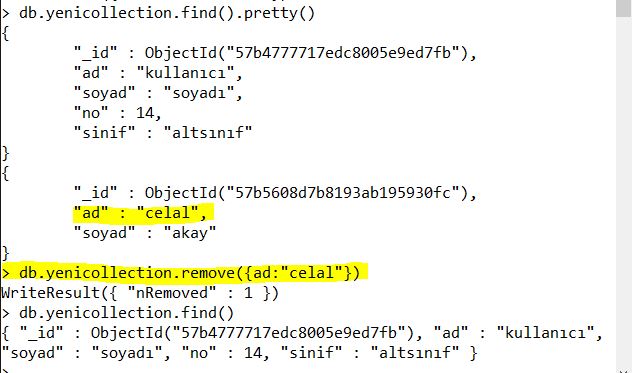
“db.collectionadi.remove({})” kod satırı yazdığınız collection içindeki tüm verileri silmek için kullanılabilir fakat siz belli bir şarta bağlı olarak veri silmek isterseniz o zaman remove parantezinin içine şartınızı belirtmeniz gerekir. şöyleki;
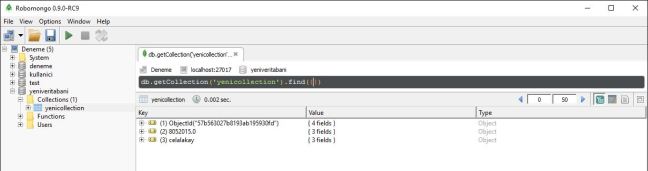
MongoDB için herhangi bir management tool isterseniz de size öneri olarak Robomongo’yu kullanmanızı tavsiye ederim kullanımı kolay ve ihtiyaçlarınıza cevap vereceğini düşünüyorum. Örnek ekran görüntüsü;